
How Cerber’s Hash Factory Works
Recently I saw a story on SecurityWeek about how the Cerber ransomware morphs every 15 seconds (each download results in a file with a new hash), which I then tracked back to the source, this article by Invincea. The various news articles made some dubious claims which can be put down to information lost in translation between reporters and an researcher or marketing, but what really piqued my interest was the fact that Invincea seemed to avoid mentioning anything about what differed between files, only that their software was still able to detect it, so of course I investigated. After downloading two files less than a second apart I was surprised to see the hash had changes because in my experience with server side malware generators, the malware is not mutated frequently to avoid heavy server load and the possible exhaustion of the algorithm, instead they change every few minutes or so.
Obviously my first thought was to open it in BinDiff and compare the function similarity in order to identify possible code mutation.
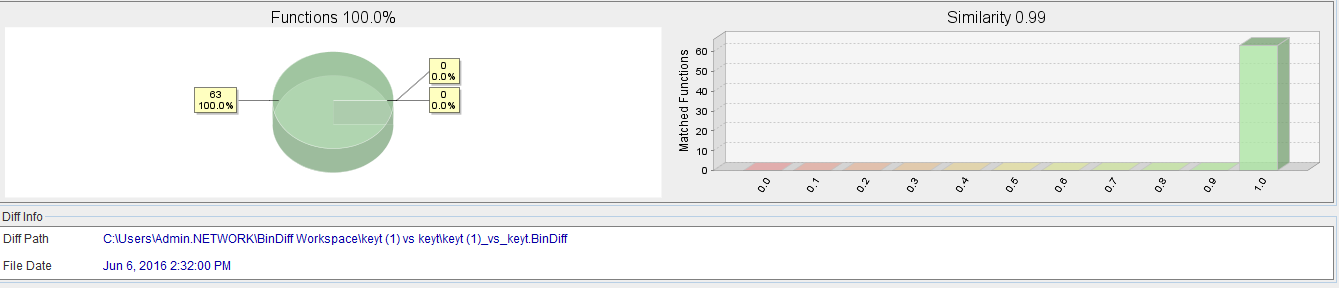
Ok, that’s weird. BinDiff reports a similarity of 0.99 but a function similarity of 100% (no code changes), so I decided a different approach was needed.
I opened both files in HXD and did a comparison and sure enough they’re different, so I searched the bytes that had changed using a binary search in IDA and found nothing, huh? At this point I realized I’d set my expectations so high that I had missed the most basic check, the EOF check (this is something I admittedly didn’t consider as it’s generally only used by scriptkiddies).
PE Editor to the rescue!
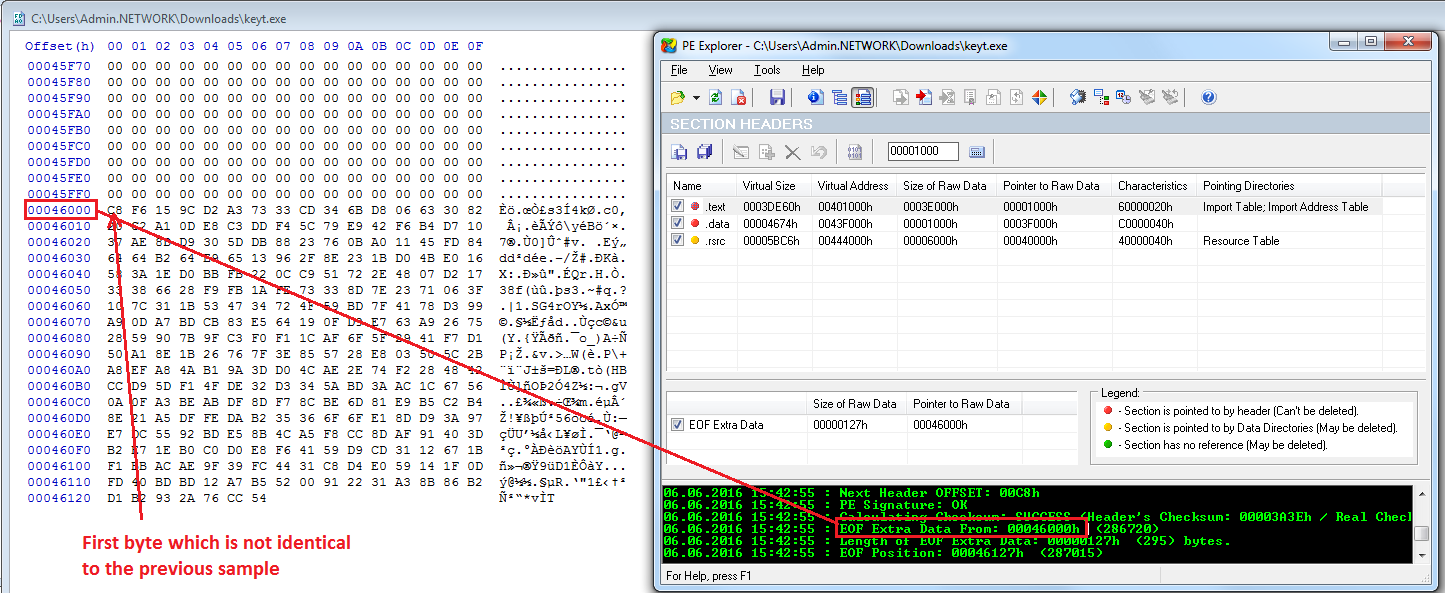 |
|---|
| Oh, ok then. |
So if you’re familiar with the PE format, you’re probably already laughing by now, but if not, let me explain: the sample is changing the file hash by writing random data after the end of the PE file, this data is not part of the executable, does not exist inside the code which is mapped into memory, and will not fool even the stupidest of modern AV scanner, it’s now pretty clear why Invincia was reluctant to mention how the samples differed.
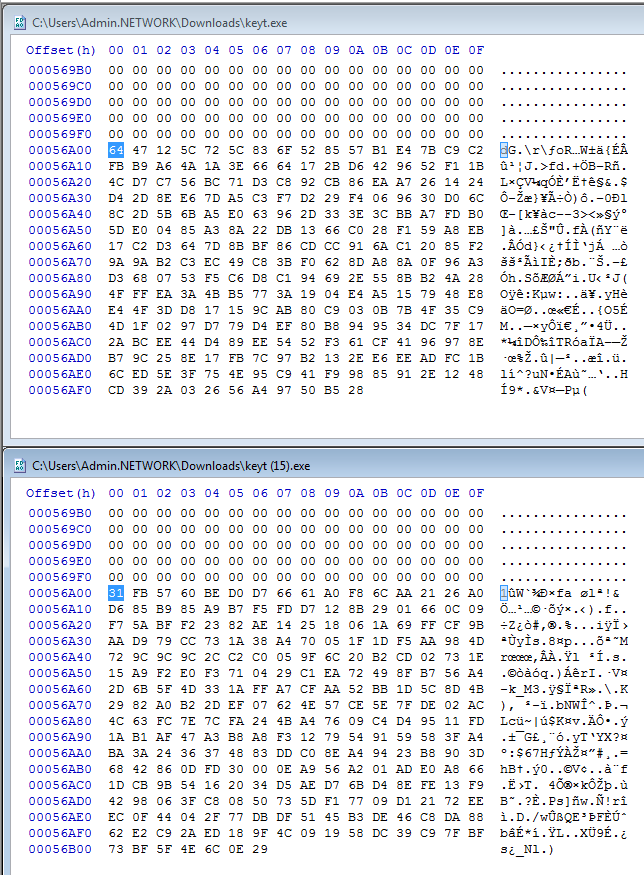 |
|---|
| The ‘hash factor’ in all its glory, a few unused random bytes at the end of the file. |
So why doesn’t this matter?
If you’re a researcher like me, you’ve probably come across AVs detecting a sample as one thing but it turns out to be another, this can be incredibly frustrating if you end up spending a day reverse engineering the wrong sample, but it’s a good thing, sort of. What AVs do is they generate signatures based on parts of the code, data, whatever, what you’re usually seeing is the AV has tagged a bit of code in one sample that is very similar to some code in another, hence the misidentification. Part of the reason you see so many samples detected as ZBot / Zeus is because it was so popular and so heavily tagged by AVs that when malware developers steal code from the leaked source (why write a banking trojan when you can copy & paste one?), their samples start getting detect as Zeus too.
Although Invincea didn’t explicitly say the hash change would fool AVs in the article, Softpedia had posted the following (which has now been fixed).> Having files with unique hashes allows Cerber to infect computers that feature antivirus products. Even if the antivirus had seen the Cerber ransomware before, it detects the threat using a list of hashes in an internal virus signature database. Because Cerber payloads get a new and unique hash every 15 seconds, it allows them to bypass basic scanning techniques.
This is simply not true, in order for adding random junk to the end of the file to bypass a scanning engine, the engine would have to be detecting files using only an entire hash of the file (not even just the PE as the EOF data resides outside of the actual executable). If any AV were to actually detect files this way it would be completely useless against all modern malware and I’d suggest firing the entire dev team, preferably into the sun. It may also be worth noting that storing data after the end of file is commonly used in old RATs and binders, which is generally an instant red flag to most antiviruses (though unless the file is written to disk before removing the EOF data, it’s unlikely to get flagged).
The only real harm to antivirus this technique is doing is the harm to some of the “cloud AV” systems which automatically upload files with hashes they haven’t seen before to their database. They’ll essentially be uploading millions of identical cerber samples until they figure out what’s going on. Just think of all that wasted bandwidth!
Conclusion
This is probably nothing more than some creative marketing, but to cover my bases I will state that the files did change significantly a few times during a couple of hours but based on the semantics of the files between changes, I’d say this is just the standard practice of frequently recrypting the payload with a new crypter to prevent detection by proper AV scanners (i.e no ones fooled by a simple hash change) and bypass heuristic detection; this is something that is common practice by all malware distributors.
All that this really does is enforce the long standing fact that hashes are only for identification of a specific sample, not all samples, all versions of a product, members of a malware family, or your cat. Malware is almost always crypted or packed with a crypter or packer which is updated constantly to avoid detection (sometimes multiple times per hour). You will always find thousands of hashes of the exact same malware binary on virustotal without some goofy EOF junk machine, nothing has changed.

